I have a RISC OS machine and a blog I actually want to write for. These two facts are not obviously compatible.
The mainstream CMS options all assume Linux, Node, PHP, a relational database, or some combination that stops working the moment you hand them a dotted path like ADFS::HardDisc4.$.CMS.content. RISC OS doesn't use / as a directory separator - it uses . - and once you notice that, you start noticing every other place in modern software where "of course the separator is a slash" is baked in so deep nobody talks about it.
So I wrote my own. Pure Python, no external dependencies, one JSON file for the database, a template engine from scratch because Jinja2 has a native C extension I didn't want to fight to compile on ARM. The whole thing is about 7000 lines.
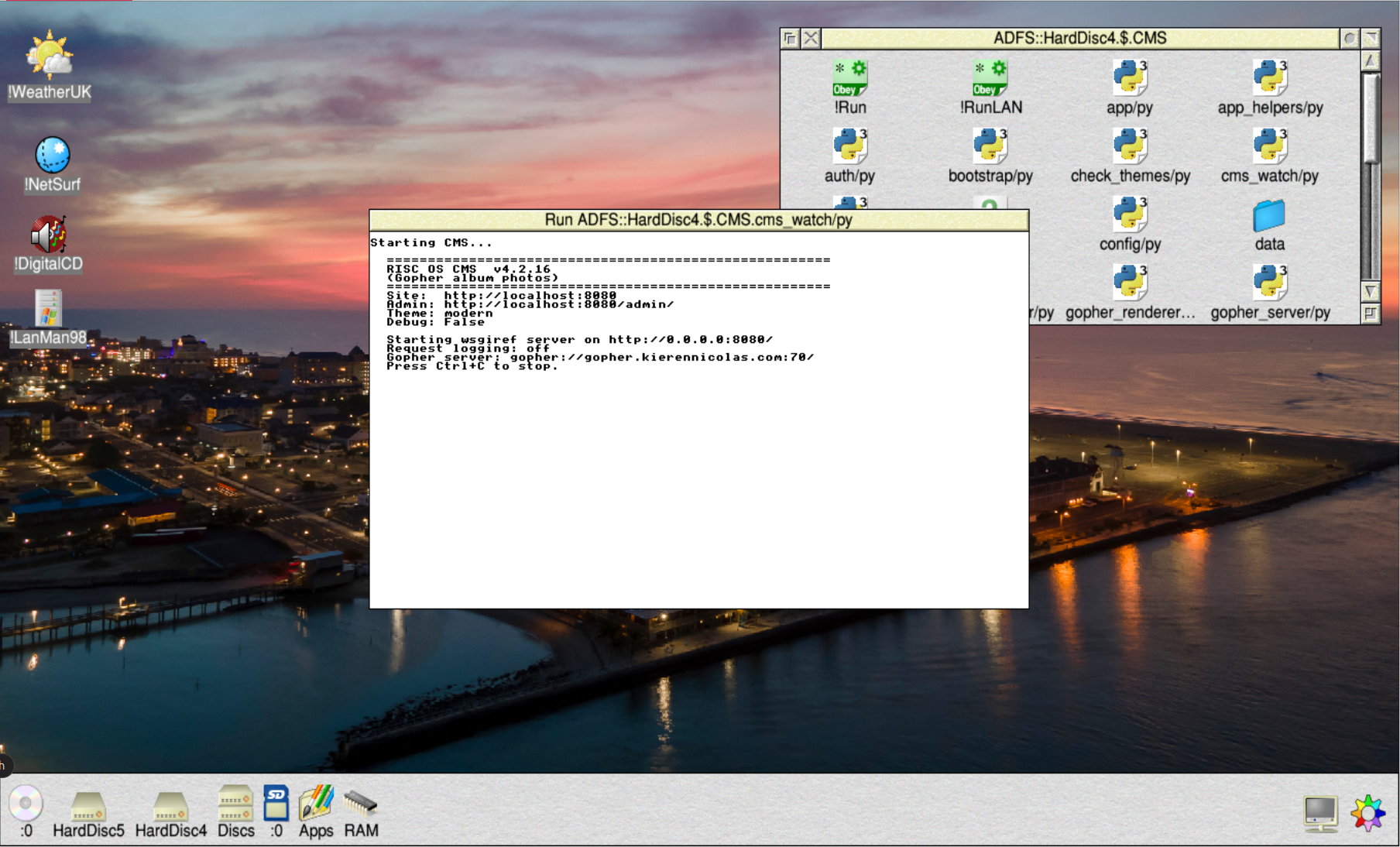
It edits content as Markdown, serves a website to visitors over HTTP, and - because the small web deserves company - also serves the same content as a Gopher capsule on port 70. Both from the same process, both reading the same database, both updating live whenever I save a post.
This is the story of how that came together, and the specific ways RISC OS keeps things interesting.

Why bother?
The honest answer is that it's a nice machine and I wanted to use it for something real.
Once you start thinking about which assumptions underpin modern software, you find yourself unable to stop. A CMS seems like it should be simple: text goes in, HTML comes out. Most of the complexity in the popular options is there to solve problems you don't have - horizontal scaling, plugin ecosystems, theme marketplaces, migration tooling. For one person writing occasional posts on a machine in their living room, none of that applies.
A CMS under those constraints turns out to be about 7000 lines of boring Python, not the 500,000 lines of exciting JavaScript that people assume a CMS has to be. That's a useful thing to know.
It's fast, runs on tin, and has barely any overhead.
Markdown
Every page and post is stored as Markdown in the JSON database. Nothing exotic - CommonMark-ish with a few conveniences. The admin editor is a <textarea> with syntax highlighting; I briefly considered something richer and then remembered I'm the only person writing into it, and I already know how to type bold.
Storing Markdown as the canonical representation turned out to matter more than I expected. HTML is lossy to convert back from, once you render Markdown to HTML, you can't reliably recover the original intent. Keeping the source as Markdown means I can render it to different targets without compromising the original. Which is what makes the Gopher side possible at all.
RISC OS leaks its assumptions everywhere
The first three weeks of the project were a grand tour of all the places Python's standard library assumes POSIX paths.

os.path.basename("photo.png") returns "png" on RISC OS. Not "photo.png". Not even a crash. Just the wrong answer, because Python's basename splits on os.sep (which is . on RISC OS) and takes the rightmost component. Every upload handler I'd written had this bug, silently. Files were being stored with single-letter filenames. "The photo filename is jpg" is a confusing error message until you work out what's happening.
The fix was a compat.http_split_ext() helper that only ever splits on / and \, never on os.sep. Seems obvious in retrospect. Wasn't obvious when I wrote it.
os.path.abspath("home.html") rewrites the path to "home/html". Because on RISC OS, .ext in a filename is a filetype marker, and RISC OS's abspath tries to be helpful by converting between the human form (home.html) and the filesystem form (home/html with a filetype stamp). The template engine called abspath() on every template path, and every template fetch was silently mangling .html into /html, then blaming the disk. The fix was to detect native RISC OS paths (they start with a disc specifier like ADFS::) and skip abspath() entirely - they're already absolute, nothing to normalise.
os.path.exists() can fault the SharedCLibrary in some RISC OS Python builds. Not return False - fault. Out goes the whole process. The fix was to never trust exists(); instead, attempt open(path, "rb") and treat the exception as the answer.
None of these are RISC OS bugs. They're correct behaviour for a non-POSIX filesystem wired up to an API that assumes POSIX. Python's stdlib did what was asked; I asked the wrong thing. Every one of these took a day to find and five minutes to fix.
After about ten of them I wrote a module called compat.py that provides RISC-OS-safe replacements for every path helper I use, plus a 35-test self-suite that runs on every startup to confirm none of them have regressed. That file is now the single most important file in the project.
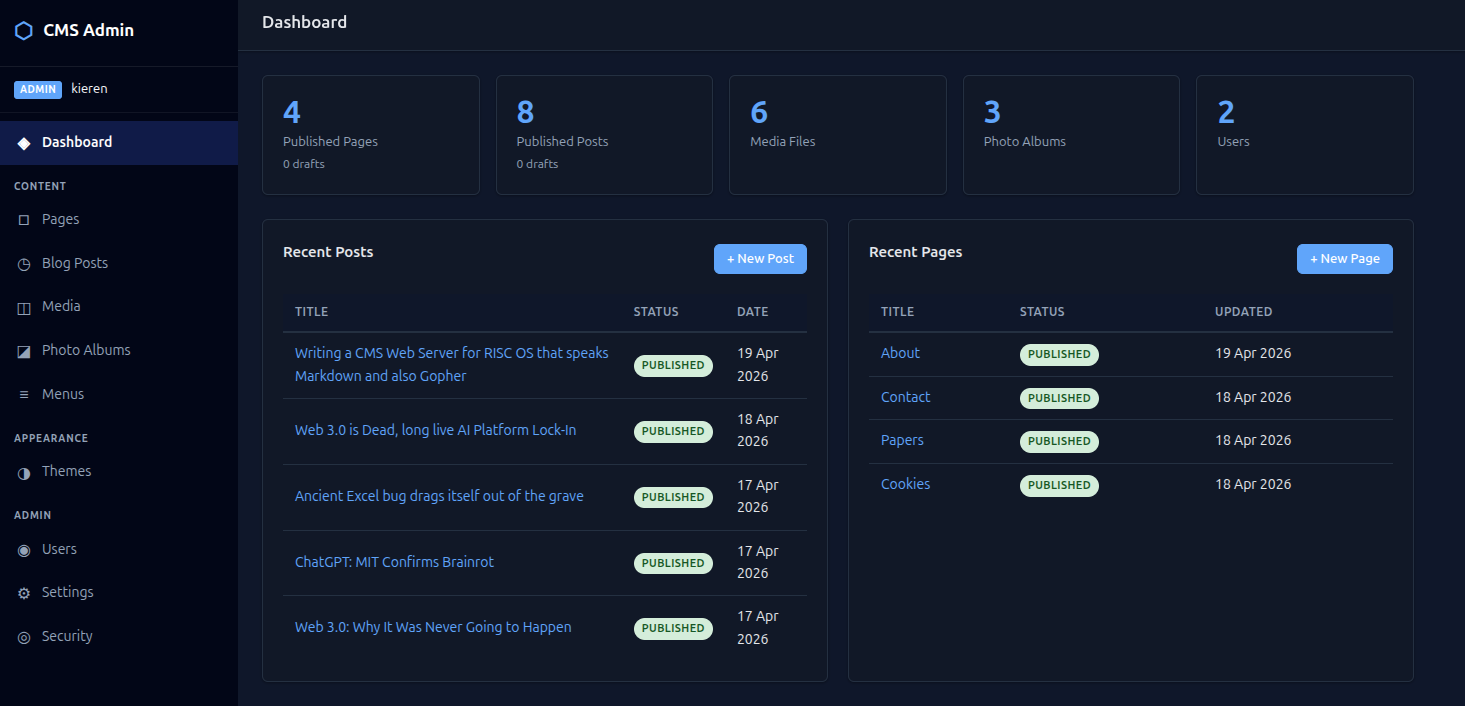
Adding Gopher, because the small web exists
Six months in, with the HTTP side stable, I added a Gopher server. Same process, background thread, separate port, reads the same database.
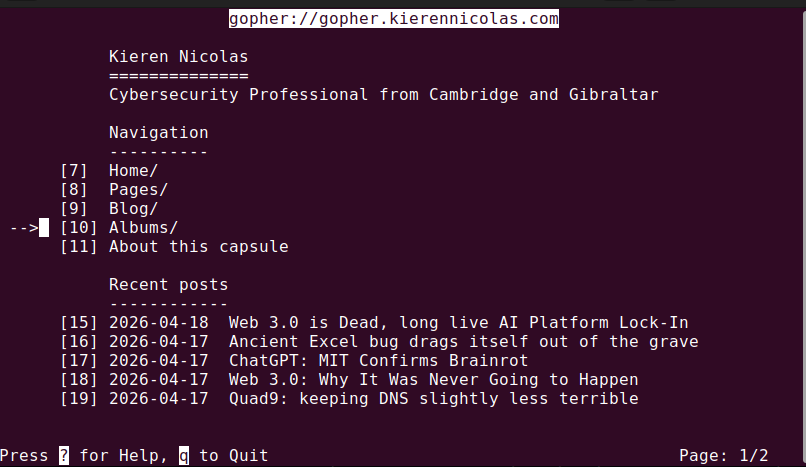
Why Gopher? Partly because I grew up with it. Partly because the protocol is about 300 bytes of specification — you can read RFC 1436 in one sitting and know the whole thing. Partly because a Gopher capsule is a quiet, readable space that doesn't require JavaScript, cookie banners, or a 4MB page weight to tell you the weather.
Mostly because if you've already got your content in Markdown, rendering it as plain text for Gopher is much less work than rendering it as HTML for the web. That turns out to be the key insight: Markdown is lossy towards HTML, but reasonably lossless towards plain text. Heading markers become underlines, bold/italic markers just get stripped, inline links become footnoted references. The information survives.
The server itself is 190 lines of Python wrapping socketserver.ThreadingTCPServer. The renderer is another 340 lines — Markdown in, wrapped plain text at 67 columns out, with a menu builder for directory listings. Every published page appears at gopher://.../pages/slug; every post at gopher://.../blog/slug; photo albums are menus of image links you can download.
There's a per-page "Hide from Gopher" checkbox for content I don't want mirrored — not that I use it, but the option is there. Drafts never appear. The whole system auto-mirrors by default, because life is too short to maintain two copies of your writing.
The Unicode incident
One surprise: my own name broke the Gopher output.
My middle name is Niĉolas - c with a circumflex, U+0109. Two bytes in UTF-8 (0xC4 0x89). The Gopher server was sending those bytes correctly on the wire. But Gopher clients from the pre-Unicode era - which is to say, most of them - interpret multi-byte sequences as Latin-1 garbage. My name was showing up as Ni�~Iolas in the client.
This is not a bug in anyone's code. It's a forty-year-old protocol meeting a character invented in 1922 via an encoding invented in 1993, and the protocol doesn't know about either.
The fix was to fold Unicode down to ASCII before sending. ĉ becomes c. é becomes e. Curly quotes become straight quotes. The pound sign becomes GBP, the degree symbol becomes deg, the em-dash becomes --. Characters with no reasonable Latin fallback — emoji, Cyrillic, CJK — become ?. The web site still displays my name correctly; only the Gopher mirror ASCII-folds.
Python's unicodedata.normalize("NFKD") does most of the work by decomposing accented characters into base + combining marks, then I strip the marks. A small manual table handles things NFKD can't decompose cleanly (smart punctuation, ligatures, currency symbols).
I added it as a regression test: seed a page titled "Naïve Café" with accents in the body, render it through the Gopher handler, assert the output bytes decode cleanly as ASCII. If I ever break this again, the tests will yell.
Certificates are someone else's problem
The HTTP side needs HTTPS, because it's 2026 and every browser will scream at visitors otherwise. That presented a problem: RISC OS Python doesn't ship with a working ssl module, so terminating TLS on the box itself wasn't an option. And even if it were, I wasn't thrilled about the prospect of running Let's Encrypt's certbot on RISC OS, renewing certificates every 90 days, and hoping nothing breaks while I'm on holiday.
Cloudflare solves this without a line of code changing on my side. Their "Flexible" SSL mode terminates TLS at their edge with a certificate they manage and auto-renew, and then makes plain-HTTP requests down to my origin. The RISC OS box never sees a TLS connection. It serves plain HTTP, identically to how it would on localhost, and Cloudflare does the modern-web bit before the traffic reaches me.
The DNS record for the HTTP site is orange-cloud, proxied, so visitors never connect to my home IP directly. They hit Cloudflare's anycast edge, Cloudflare fetches from my origin, and the round trip looks like it's coming from Cloudflare's network. The router forwards a single HTTP port to the RISC OS box for Cloudflare's edge to reach, and that's the entire public-facing footprint for the web side.
Flexible mode has a known tradeoff: the segment between Cloudflare and my origin is plaintext, so someone with a tap on that link could theoretically see traffic in flight. "Full" or "Full (Strict)" modes fix that by requiring an origin certificate, but that brings me back to needing a working ssl module on RISC OS - the problem I started from. Flexible is the pragmatic choice given the constraint, and for a personal site with no login flow facing the public and no sensitive data in transit, the threat model sits comfortably.
The contrast with Gopher is quietly satisfying. The Gopher DNS record is grey-cloud - DNS only, no proxy - because Cloudflare's proxy only speaks HTTP. Port 70 is forwarded at the router straight to the RISC OS box, and visitors connect directly with no intermediary. That exposes device IP for Gopher traffic, but Gopher is a trust-nothing protocol by design: there's no session to hijack, no credentials to exfiltrate, no cookies to steal. For HTTP, the layered CDN treatment felt worth it.
What works, six months in
The site is stable. Publishing a post means opening the admin UI, typing Markdown, clicking save. It appears on the web immediately. It appears on Gopher within milliseconds (same database, no separate build step). Photo albums work on both. Tags and post metadata round-trip through both. The admin is CSRF-protected, CSP-locked down, and has no external dependencies - no CDN, no Google Fonts, no analytics. Nothing leaves my machine except the pages visitors request.
Running it on an ARM machine, serving both HTTP and Gopher from the same thirty-watt box, with the source formats being Markdown files stored as JSON: it shouldn't work. It works.
The broader point
I didn't set out to prove anything ideological about small computers or small protocols. I set out to publish writing from a machine I like using.
But I ended up with a system that's easier to understand end-to-end than any CMS I've worked with professionally. The whole codebase fits in my head. The dependencies are Python's standard library. The database is a JSON file I can edit by hand if I need to. The Gopher server and the HTTP server read the same content through the same code path. There's no deployment pipeline because there's nothing to deploy — I edit the files, I restart the process, it works.
Modern software has lost something by pretending the only sensible substrate is Linux, the only sensible frontend is a SPA, and the only sensible publishing format is whatever the biggest three vendors agreed on last quarter. You can make interesting things without any of that. Sometimes the constraint is the interesting thing.
---
The CMS is a personal project — I use it to run this site. If you want to talk about RISC OS, Gopher, minimalism in software, or why your own CMS might be simpler than you think, get in touch. I'll even talk a little bit about Cyber stuff too :D