Introduction
In my last Web 3.0 article, Web 3.0: Why It Was Never Going to Happen, I argued that Web 3.0 failed because it tried to push decentralisation into an internet that had already been reorganised around platforms, managed ecosystems, and convenience-first dependency. That argument still stands. NIST describes Web3 as a proposed restructuring of the internet that would place ownership and operation more directly in the hands of users, with decentralised systems, user-managed data, and token-based assets and payments at the centre of the model.[1], [2] The problem was never that these ideas were impossible to describe. The problem was that they were introduced into a networked world that had already moved in the opposite direction.

The older internet, and later the Web built on top of it, grew out of a more openly networked tradition. It was started as a system for information sharing across different computers, while the Internet Society’s history makes equally clear that the internet itself pre-dated the Web and evolved from earlier packet-switched networking and open standards work.[3], [4]
In other words, the Web was an application layer built on top of a broader network, not the network itself. That's important, because much of what people nostalgically remember as the “old web” was really a wider culture of interoperable protocols.
That older model was imperfect, but it encouraged movement between clients, systems, and providers in a way that today’s internet often does not. Internet Relay Chat was standardised as a text-based conferencing protocol, and XMPP’s Jingle extensions were explicitly designed to negotiate peer-to-peer media sessions over an open signalling channel.[5], [6] These systems were not utopian, and they did not solve every problem, but they did embody a design assumption that now feels almost quaint: different systems should be able to talk to each other without every interaction being routed through a single vendor’s commercial enclosure.
Web 3.0 misread the direction of travel
Web 3.0 was pitched as an answer to centralisation, but it arrived after centralisation had already become the dominant commercial logic of the consumer internet. That is precisely why its promises sounded better in theory than in practice. If users had already become accustomed to identity managed by major providers, software distribution controlled by app stores, and cloud services wrapped in provider-specific abstractions, a model that asked them to manage wallets, keys, tokens, and unfamiliar trust assumptions was always going to be a hard sell.[1], [2], [7]
There is also a more basic point here. Interoperability and portability are not accidental features that appear on their own once the market becomes sufficiently enlightened. NIST has repeatedly treated interoperability and portability as explicit cloud-computing concerns, and has linked portability work to reducing the risk of vendor lock-in.[7], [8] It is a recognised structural issue. Web 3.0 offered a rhetorical answer to that issue, but it did not appear in an environment that rewarded such an answer.
Platform lock-in did not end. It matured
By the time Web 3.0 was making grand claims about decentralisation, software distribution on mobile devices had already been normalised as a governed activity. Apple’s App Review Guidelines and app-review process make clear that apps, updates, in-app purchases, and related content are reviewed against Apple’s technical, business, design, legal, and safety requirements before they can remain in the App Store.[9], [10] Google Play is different in detail, but not in substance. Google’s Developer Policy Center presents app distribution as something conducted under platform rules designed to determine what may be offered to users and on what terms.[11]
This is not a side issue. It is one of the main reasons why modern lock-in feels so durable. Earlier internet culture was built around protocols that allowed many competing clients to interoperate. Modern platform culture is increasingly built around controlled marketplaces, governed identities, subscription relationships, and provider-defined policy frameworks. A decentralised rhetoric was never likely to dislodge that system by force of enthusiasm alone. Web 3.0 did not fail because nobody could explain decentralisation. It failed because centralisation had already become the norm.
Artificial Intelligence fits better than Web 3.0 ever did
Artificial Intelligence does not challenge this, in fact it runs with it. Web 3.0 asked users to take on more direct responsibility. Artificial Intelligence offers the opposite bargain. It invites users to stay inside a managed interface and let the system mediate search, drafting, summarisation, synthesis, and retrieval on their behalf. That is a much easier proposition to sell, because it reduces effort at the same moment that it increases dependence. It then makes the AI the gatekeeper.
Mainstream search platforms are already well aware. Google states that AI Overviews in Search can “take the work out of searching” by providing AI-generated snapshots with key information and links, and it has continued to expand AI Overviews and AI Mode as part of the Search experience.[12], [13], [14] OpenAI, similarly, describes ChatGPT search and research tools as ways to search, analyse, and synthesise information from across the web, and presents that synthesis as a primary feature rather than a side utility.[15], [16], [17] None of this is hidden. The direction of travel is stated openly: the user should do less of the legwork, and the system should do more of the interpretive work.
That is why AI aligns so comfortably with platform logic. App stores centralised distribution. Cloud platforms centralised infrastructure. Identity platforms centralised access. Gen AI now centralises mediation. It does not merely host the service. It increasingly stands between the user and the underlying material, offering a cleaned-up answer in place of a messier encounter with sources, tools, and competing claims.[12], [15], [17]. You know, when the user had to think and critically understand, sort, and go through the information.
The browser is not the window
This has consequences for how people experience the internet. The classic browser model assumed that a user would search, click, compare, navigate, and decide. The user might do that well or badly, but the basic relationship was direct. The browser was a window onto documents, services, and other people’s systems. A search engine could shape discovery, certainly, but it still largely sent the user somewhere else.
The AI-mediated model changes that balance. Google’s own documentation now treats AI features such as AI Overviews and AI Mode as part of the Search experience, while its consumer-facing help material says AI Overviews provide AI-generated snapshots designed to make search faster and easier.[12], [13] OpenAI’s product material likewise frames search and research as a way to bring together information from across the web into a synthesised result.[15], [17]
In both cases, the emphasis is not on sending the user outward into a broad field of destinations, but on reducing the need to travel across that field in the first place.
There is an obvious benefit here, and it would be silly to deny it. Some tasks really are better served by a decent summary than by forcing a human being to trawl through six layers of muddled vendor prose. The problem is not that synthesis is always bad. The problem is that an internet built around synthesis changes the role of the user. It encourages the user to become less of a navigator and more of a requester.
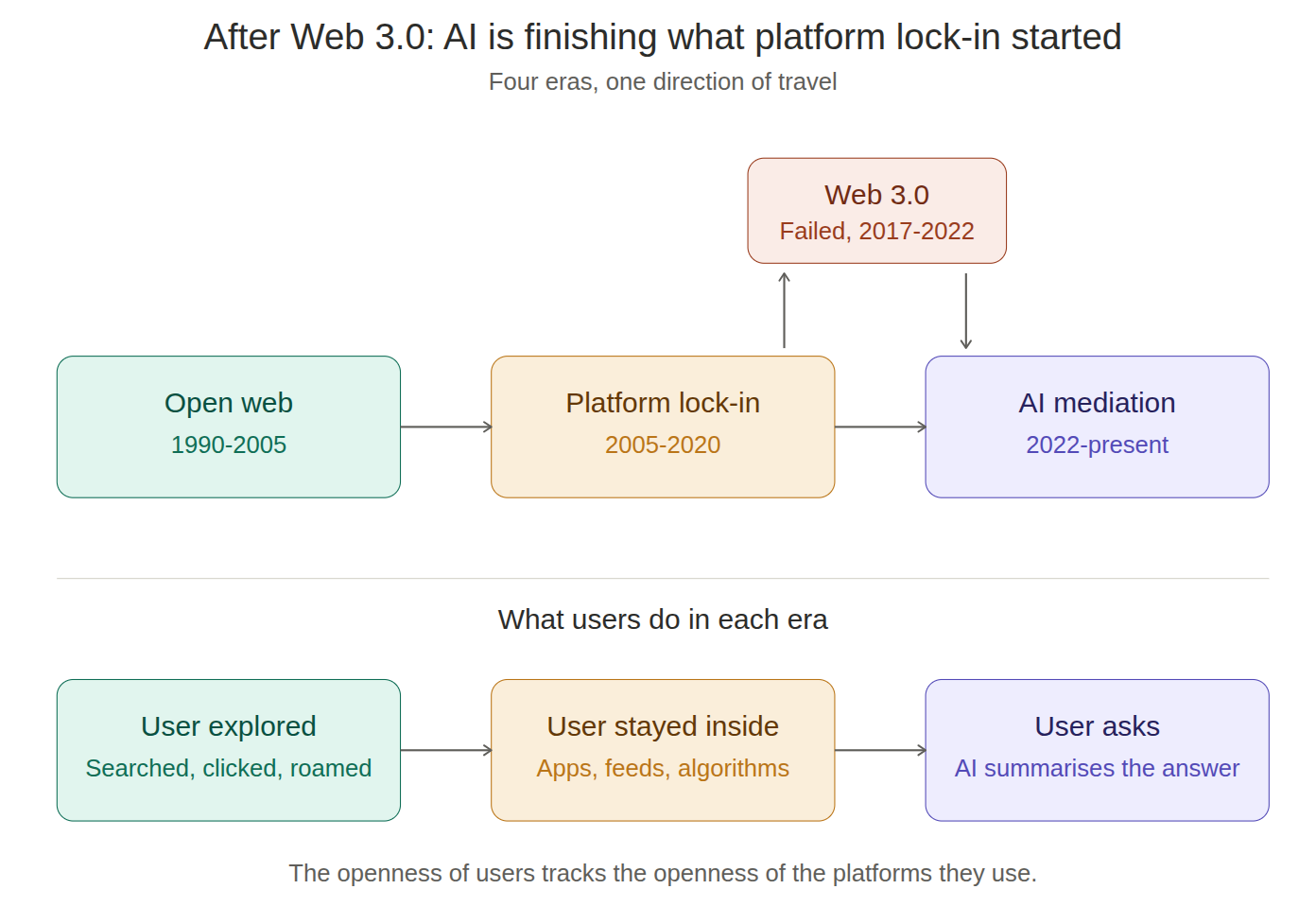
What gets lost when mediation becomes normal
Once that change becomes habitual, the effect is larger than a mere interface tweak. The open web depends on people actually visiting things. Independent sites, forums, documentation pages, blogs, and publications retain value because users arrive there, read them in context, contibute their own information, and sometimes wander somewhere unexpected afterwards. When the dominant interaction becomes “ask here, receive summary here,” the destination starts to matter less than the intermediary. The source is still present, but increasingly as material to be extracted rather than a place to be encountered.[12], [13], [17]
This is one reason the comparison with Web 3.0 matters. Web 3.0 at least claimed to be trying to restore a more user-centric internet.[1], [2] AI does not need to make that promise. It can succeed without returning agency, portability, or interoperability to the user, because its offer is not freedom but convenience. It asks very little of the user beyond trust, continued use, and a willingness to let the system mediate more of the interaction. That is a much better fit for an internet already shaped by lock-in.
The result is not necessarily the death of the web. It is something subtler and arguably stranger. The web remains there, just as the underlying network remains there, but the user’s relationship to it becomes increasingly indirect. The open, link-following, protocol-rich internet is not abolished overnight. It is gradually hidden behind providers that promise to spare users the trouble of dealing with it directly.[3], [4], [12], [15]
Summary
Web 3.0 failed because it tried to reverse an economic and cultural shift that had already happened. It proposed a more decentralised and user-centric internet after the market had already settled on app stores, governed platforms, provider-specific cloud abstractions, and identity systems that reward staying put.[1], [2], [7], [9], [11]
That is why Artificial Intelligence is finishing what platform lock-in started. It is not simply another fashionable technology layer. It is an efficient way of consolidating mediation. Search becomes synthesis. Browsing becomes prompting. Discovery becomes managed response. The user is no longer encouraged to roam the network so much as to ask a resident intermediary to roam it on their behalf.[12], [13], [15], [17]
Web 3.0 promised ownership and did not deliver it. Artificial Intelligence promises convenience and it will deliver it. [7], [8], [12], [15]
It will be a strange future, and a very hard one to predict. These AI gatekeepers really do need excellent oversight, but without it, the direction of travel is clear.
All hail our AI overlords. Just don't look for the answer yourself.
References
[1] NIST Computer Security Resource Center, “Web3,” NIST CSRC Glossary. [Online]. Available: https://csrc.nist.gov/glossary/term/web3. [Accessed: Apr. 18, 2026].
[2] D. Yaga and P. Mell, A Security Perspective on the Web3 Paradigm, NIST IR 8475, National Institute of Standards and Technology, Feb. 2025. [Online]. Available: https://csrc.nist.gov/pubs/ir/8475/final. [Accessed: Apr. 18, 2026].
[3] CERN, “The birth of the Web.” [Online]. Available: https://home.web.cern.ch/science/computing/birth-web. [Accessed: Apr. 18, 2026].
[4] B. Leiner et al., “A Brief History of the Internet,” Internet Society. [Online]. Available: https://www.internetsociety.org/internet/history-internet/brief-history-internet/. [Accessed: Apr. 18, 2026].
[5] J. Oikarinen and D. Reed, “RFC 1459: Internet Relay Chat Protocol,” RFC Editor, May 1993. [Online]. Available: https://www.rfc-editor.org/rfc/rfc1459.html. [Accessed: Apr. 18, 2026].
[6] XMPP Standards Foundation, “XEP-0166: Jingle,” Nov. 2018. [Online]. Available: https://xmpp.org/extensions/xep-0166.html. [Accessed: Apr. 18, 2026].
[7] National Institute of Standards and Technology, NIST Cloud Computing Standards Roadmap, NIST SP 500-291, vol. 1. [Online]. Available: https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication500-291v1.pdf. [Accessed: Apr. 18, 2026].
[8] National Institute of Standards and Technology, “NIST Cloud Computing Program (NCCP).” [Online]. Available: https://www.nist.gov/programs-projects/nist-cloud-computing-program-nccp. [Accessed: Apr. 18, 2026].
[9] Apple, “App Review Guidelines.” [Online]. Available: https://developer.apple.com/app-store/review/guidelines/. [Accessed: Apr. 18, 2026].
[10] Apple, “App Review.” [Online]. Available: https://developer.apple.com/distribute/app-review/. [Accessed: Apr. 18, 2026].
[11] Google, “Developer Policy Center,” Google Play. [Online]. Available: https://play.google.com/intl/en/about/developer-content-policy/. [Accessed: Apr. 18, 2026].
[12] Google, “Find information in faster & easier ways with AI Overviews in Google Search.” [Online]. Available: https://support.google.com/websearch/answer/14901683?hl=en. [Accessed: Apr. 18, 2026].
[13] Google, “AI features and your website,” Google Search Central. [Online]. Available: https://developers.google.com/search/docs/appearance/ai-features. [Accessed: Apr. 18, 2026].
[14] R. Stein, “Just ask anything: a seamless new Search experience,” Google Blog, Jan. 27, 2026. [Online]. Available: https://blog.google/products-and-platforms/products/search/ai-mode-ai-overviews-updates/. [Accessed: Apr. 18, 2026].
[15] OpenAI, “Introducing ChatGPT search,” Oct. 31, 2024, updated Feb. 5, 2025. [Online]. Available: https://openai.com/index/introducing-chatgpt-search/. [Accessed: Apr. 18, 2026].
[16] OpenAI Help Center, “How to search in ChatGPT.” [Online]. Available: https://help.openai.com/en/articles/9237897-chatgpt-search. [Accessed: Apr. 18, 2026].
[17] OpenAI Academy, “Research with ChatGPT,” Apr. 10, 2026. [Online]. Available: https://openai.com/academy/search-and-deep-research/. [Accessed: Apr. 18, 2026].